05 - Torch Connector and Hybrid QNNs
[1]:
# this code is from:
# https://qiskit-community.github.io/qiskit-machine-learning/tutorials/05_torch_connector.html
[2]:
# Necessary imports
import numpy as np
import matplotlib.pyplot as plt
from torch import Tensor
from torch.nn import Linear, CrossEntropyLoss, MSELoss
from torch.optim import LBFGS
from qiskit import QuantumCircuit
from qiskit.circuit import Parameter
from qiskit.circuit.library import RealAmplitudes, ZZFeatureMap
from qiskit_machine_learning.utils import algorithm_globals
#from qiskit_machine_learning.neural_networks import SamplerQNN, EstimatorQNN
from qiskit_machine_learning.connectors import TorchConnector
# Set seed for random generators
algorithm_globals.random_seed = 42
# Import from Quantum Rings Toolkit
from quantumrings.toolkit.qiskit.machine_learning import QrEstimatorQNN as EstimatorQNN
from quantumrings.toolkit.qiskit.machine_learning import QrSamplerQNN as SamplerQNN
[3]:
# Generate random dataset
# Select dataset dimension (num_inputs) and size (num_samples)
num_inputs = 2
num_samples = 20
# Generate random input coordinates (X) and binary labels (y)
X = 2 * algorithm_globals.random.random([num_samples, num_inputs]) - 1
y01 = 1 * (np.sum(X, axis=1) >= 0) # in { 0, 1}, y01 will be used for SamplerQNN example
y = 2 * y01 - 1 # in {-1, +1}, y will be used for EstimatorQNN example
# Convert to torch Tensors
X_ = Tensor(X)
y01_ = Tensor(y01).reshape(len(y)).long()
y_ = Tensor(y).reshape(len(y), 1)
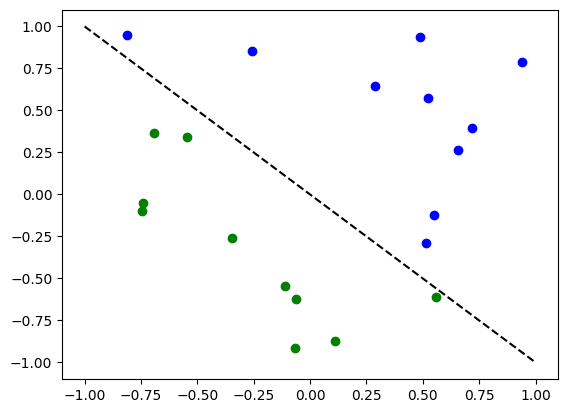
# Plot dataset
for x, y_target in zip(X, y):
if y_target == 1:
plt.plot(x[0], x[1], "bo")
else:
plt.plot(x[0], x[1], "go")
plt.plot([-1, 1], [1, -1], "--", color="black")
plt.show()
[4]:
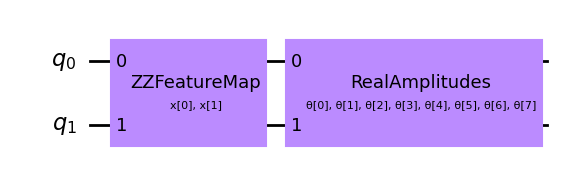
# Set up a circuit
feature_map = ZZFeatureMap(num_inputs)
ansatz = RealAmplitudes(num_inputs)
qc = QuantumCircuit(num_inputs)
qc.compose(feature_map, inplace=True)
qc.compose(ansatz, inplace=True)
qc.draw(output="mpl", style="clifford")
[4]:
[5]:
# Setup QNN
qnn1 = EstimatorQNN(
circuit=qc, input_params=feature_map.parameters, weight_params=ansatz.parameters
)
# Set up PyTorch module
# Note: If we don't explicitly declare the initial weights
# they are chosen uniformly at random from [-1, 1].
initial_weights = 0.1 * (2 * algorithm_globals.random.random(qnn1.num_weights) - 1)
model1 = TorchConnector(qnn1, initial_weights=initial_weights)
print("Initial weights: ", initial_weights)
Initial weights: [-0.01256962 0.06653564 0.04005302 -0.03752667 0.06645196 0.06095287
-0.02250432 -0.04233438]
[6]:
# Test with a single input
model1(X_[0, :])
[6]:
tensor([-0.3285], grad_fn=<_TorchNNFunctionBackward>)
[7]:
# Define optimizer and loss
optimizer = LBFGS(model1.parameters())
f_loss = MSELoss(reduction="sum")
# Start training
model1.train() # set model to training mode
# Note from (https://pytorch.org/docs/stable/optim.html):
# Some optimization algorithms such as LBFGS need to
# reevaluate the function multiple times, so you have to
# pass in a closure that allows them to recompute your model.
# The closure should clear the gradients, compute the loss,
# and return it.
def closure():
optimizer.zero_grad() # Initialize/clear gradients
loss = f_loss(model1(X_), y_) # Evaluate loss function
loss.backward() # Backward pass
print(loss.item()) # Print loss
return loss
# Run optimizer step4
optimizer.step(closure)
25.535646438598633
22.696760177612305
20.039228439331055
19.687908172607422
19.267208099365234
19.025373458862305
18.154708862304688
17.337854385375977
19.082578659057617
17.073287963867188
16.21839141845703
14.992582321166992
14.929339408874512
14.914533615112305
14.907636642456055
14.902364730834961
14.902134895324707
14.90211009979248
14.902111053466797
[7]:
tensor(25.5356, grad_fn=<MseLossBackward0>)
[8]:
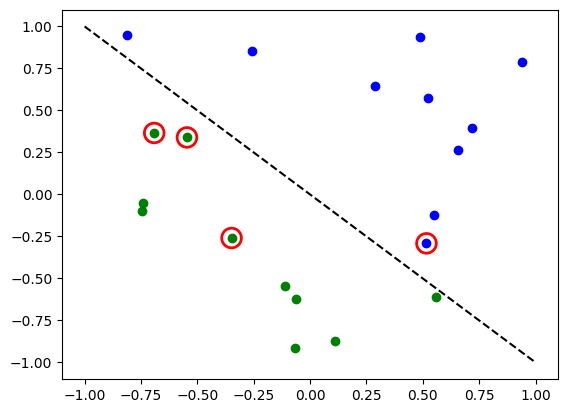
# Evaluate model and compute accuracy
model1.eval()
y_predict = []
for x, y_target in zip(X, y):
output = model1(Tensor(x))
y_predict += [np.sign(output.detach().numpy())[0]]
print("Accuracy:", sum(y_predict == y) / len(y))
# Plot results
# red == wrongly classified
for x, y_target, y_p in zip(X, y, y_predict):
if y_target == 1:
plt.plot(x[0], x[1], "bo")
else:
plt.plot(x[0], x[1], "go")
if y_target != y_p:
plt.scatter(x[0], x[1], s=200, facecolors="none", edgecolors="r", linewidths=2)
plt.plot([-1, 1], [1, -1], "--", color="black")
plt.show()
Accuracy: 0.8
[9]:
# Define feature map and ansatz
feature_map = ZZFeatureMap(num_inputs)
ansatz = RealAmplitudes(num_inputs, entanglement="linear", reps=1)
# Define quantum circuit of num_qubits = input dim
# Append feature map and ansatz
qc = QuantumCircuit(num_inputs)
qc.compose(feature_map, inplace=True)
qc.compose(ansatz, inplace=True)
# Define SamplerQNN and initial setup
parity = lambda x: "{:b}".format(x).count("1") % 2 # optional interpret function
output_shape = 2 # parity = 0, 1
qnn2 = SamplerQNN(
circuit=qc,
input_params=feature_map.parameters,
weight_params=ansatz.parameters,
interpret=parity,
output_shape=output_shape,
)
# Set up PyTorch module
# Reminder: If we don't explicitly declare the initial weights
# they are chosen uniformly at random from [-1, 1].
initial_weights = 0.1 * (2 * algorithm_globals.random.random(qnn2.num_weights) - 1)
print("Initial weights: ", initial_weights)
model2 = TorchConnector(qnn2, initial_weights)
Initial weights: [ 0.0364991 -0.0720495 -0.06001836 -0.09852755]
[10]:
# Define model, optimizer, and loss
optimizer = LBFGS(model2.parameters())
f_loss = CrossEntropyLoss() # Our output will be in the [0,1] range
# Start training
model2.train()
# Define LBFGS closure method (explained in previous section)
def closure():
optimizer.zero_grad(set_to_none=True) # Initialize gradient
loss = f_loss(model2(X_), y01_) # Calculate loss
loss.backward() # Backward pass
print(loss.item()) # Print loss
return loss
# Run optimizer (LBFGS requires closure)
optimizer.step(closure);
0.6916710138320923
0.6880060434341431
0.726793110370636
0.6573318243026733
0.6550102829933167
0.6474725604057312
0.6428855657577515
0.6700577139854431
0.6274703741073608
0.6237815022468567
0.6274160146713257
0.66053307056427
0.6234461069107056
0.6212972402572632
0.6144043207168579
0.6167712807655334
0.6156728267669678
0.6198592185974121
0.615470826625824
0.6298598051071167
[11]:
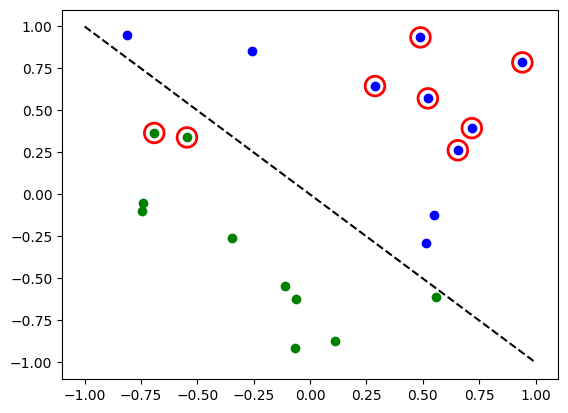
# Evaluate model and compute accuracy
model2.eval()
y_predict = []
for x in X:
output = model2(Tensor(x))
y_predict += [np.argmax(output.detach().numpy())]
print("Accuracy:", sum(y_predict == y01) / len(y01))
# plot results
# red == wrongly classified
for x, y_target, y_ in zip(X, y01, y_predict):
if y_target == 1:
plt.plot(x[0], x[1], "bo")
else:
plt.plot(x[0], x[1], "go")
if y_target != y_:
plt.scatter(x[0], x[1], s=200, facecolors="none", edgecolors="r", linewidths=2)
plt.plot([-1, 1], [1, -1], "--", color="black")
plt.show()
Accuracy: 0.75
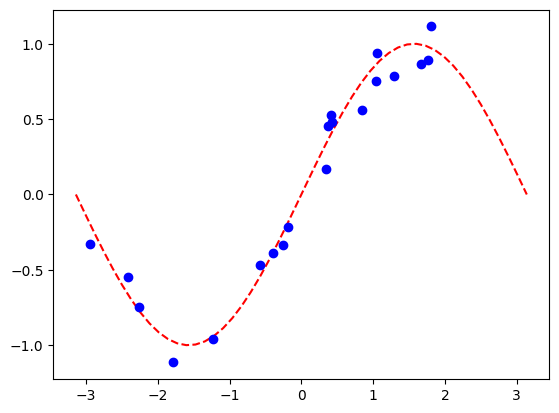
[12]:
# Generate random dataset
num_samples = 20
eps = 0.2
lb, ub = -np.pi, np.pi
f = lambda x: np.sin(x)
X = (ub - lb) * algorithm_globals.random.random([num_samples, 1]) + lb
y = f(X) + eps * (2 * algorithm_globals.random.random([num_samples, 1]) - 1)
plt.plot(np.linspace(lb, ub), f(np.linspace(lb, ub)), "r--")
plt.plot(X, y, "bo")
plt.show()
[13]:
# Construct simple feature map
param_x = Parameter("x")
feature_map = QuantumCircuit(1, name="fm")
feature_map.ry(param_x, 0)
# Construct simple parameterized ansatz
param_y = Parameter("y")
ansatz = QuantumCircuit(1, name="vf")
ansatz.ry(param_y, 0)
qc = QuantumCircuit(1)
qc.compose(feature_map, inplace=True)
qc.compose(ansatz, inplace=True)
# Construct QNN
qnn3 = EstimatorQNN(circuit=qc, input_params=[param_x], weight_params=[param_y])
# Set up PyTorch module
# Reminder: If we don't explicitly declare the initial weights
# they are chosen uniformly at random from [-1, 1].
initial_weights = 0.1 * (2 * algorithm_globals.random.random(qnn3.num_weights) - 1)
model3 = TorchConnector(qnn3, initial_weights)
[14]:
# Define optimizer and loss function
optimizer = LBFGS(model3.parameters())
f_loss = MSELoss(reduction="sum")
# Start training
model3.train() # set model to training mode
# Define objective function
def closure():
optimizer.zero_grad(set_to_none=True) # Initialize gradient
loss = f_loss(model3(Tensor(X)), Tensor(y)) # Compute batch loss
loss.backward() # Backward pass
print(loss.item()) # Print loss
return loss
# Run optimizer
optimizer.step(closure)
14.947757720947266
2.948650360107422
8.952412605285645
0.37905153632164
0.24995625019073486
0.2483610212802887
0.24835753440856934
[14]:
tensor(14.9478, grad_fn=<MseLossBackward0>)
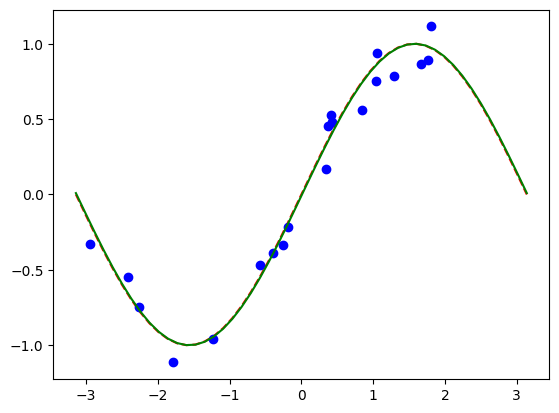
[15]:
# Plot target function
plt.plot(np.linspace(lb, ub), f(np.linspace(lb, ub)), "r--")
# Plot data
plt.plot(X, y, "bo")
# Plot fitted line
model3.eval()
y_ = []
for x in np.linspace(lb, ub):
output = model3(Tensor([x]))
y_ += [output.detach().numpy()[0]]
plt.plot(np.linspace(lb, ub), y_, "g-")
plt.show()
[16]:
# Additional torch-related imports
import torch
from torch import cat, no_grad, manual_seed
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import torch.optim as optim
from torch.nn import (
Module,
Conv2d,
Linear,
Dropout2d,
NLLLoss,
MaxPool2d,
Flatten,
Sequential,
ReLU,
)
import torch.nn.functional as F
[17]:
# Train Dataset
# -------------
# Set train shuffle seed (for reproducibility)
manual_seed(42)
batch_size = 1
n_samples = 100 # We will concentrate on the first 100 samples
# Use pre-defined torchvision function to load MNIST train data
X_train = datasets.MNIST(
root="./data", train=True, download=True, transform=transforms.Compose([transforms.ToTensor()])
)
# Filter out labels (originally 0-9), leaving only labels 0 and 1
idx = np.append(
np.where(X_train.targets == 0)[0][:n_samples], np.where(X_train.targets == 1)[0][:n_samples]
)
X_train.data = X_train.data[idx]
X_train.targets = X_train.targets[idx]
# Define torch dataloader with filtered data
train_loader = DataLoader(X_train, batch_size=batch_size, shuffle=True)
[18]:
n_samples_show = 6
data_iter = iter(train_loader)
fig, axes = plt.subplots(nrows=1, ncols=n_samples_show, figsize=(10, 3))
while n_samples_show > 0:
images, targets = data_iter.__next__()
axes[n_samples_show - 1].imshow(images[0, 0].numpy().squeeze(), cmap="gray")
axes[n_samples_show - 1].set_xticks([])
axes[n_samples_show - 1].set_yticks([])
axes[n_samples_show - 1].set_title("Labeled: {}".format(targets[0].item()))
n_samples_show -= 1

[19]:
# Test Dataset
# -------------
# Set test shuffle seed (for reproducibility)
# manual_seed(5)
n_samples = 50
# Use pre-defined torchvision function to load MNIST test data
X_test = datasets.MNIST(
root="./data", train=False, download=True, transform=transforms.Compose([transforms.ToTensor()])
)
# Filter out labels (originally 0-9), leaving only labels 0 and 1
idx = np.append(
np.where(X_test.targets == 0)[0][:n_samples], np.where(X_test.targets == 1)[0][:n_samples]
)
X_test.data = X_test.data[idx]
X_test.targets = X_test.targets[idx]
# Define torch dataloader with filtered data
test_loader = DataLoader(X_test, batch_size=batch_size, shuffle=True)
[20]:
# Define and create QNN
def create_qnn():
feature_map = ZZFeatureMap(2)
ansatz = RealAmplitudes(2, reps=1)
qc = QuantumCircuit(2)
qc.compose(feature_map, inplace=True)
qc.compose(ansatz, inplace=True)
# REMEMBER TO SET input_gradients=True FOR ENABLING HYBRID GRADIENT BACKPROP
qnn = EstimatorQNN(
circuit=qc,
input_params=feature_map.parameters,
weight_params=ansatz.parameters,
input_gradients=True,
)
return qnn
qnn4 = create_qnn()
[21]:
# Define torch NN module
class Net(Module):
def __init__(self, qnn):
super().__init__()
self.conv1 = Conv2d(1, 2, kernel_size=5)
self.conv2 = Conv2d(2, 16, kernel_size=5)
self.dropout = Dropout2d()
self.fc1 = Linear(256, 64)
self.fc2 = Linear(64, 2) # 2-dimensional input to QNN
self.qnn = TorchConnector(qnn) # Apply torch connector, weights chosen
# uniformly at random from interval [-1,1].
self.fc3 = Linear(1, 1) # 1-dimensional output from QNN
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.max_pool2d(x, 2)
x = F.relu(self.conv2(x))
x = F.max_pool2d(x, 2)
x = self.dropout(x)
x = x.view(x.shape[0], -1)
x = F.relu(self.fc1(x))
x = self.fc2(x)
x = self.qnn(x) # apply QNN
x = self.fc3(x)
return cat((x, 1 - x), -1)
model4 = Net(qnn4)
[22]:
# Define model, optimizer, and loss function
optimizer = optim.Adam(model4.parameters(), lr=0.001)
loss_func = NLLLoss()
# Start training
epochs = 10 # Set number of epochs
loss_list = [] # Store loss history
model4.train() # Set model to training mode
for epoch in range(epochs):
total_loss = []
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad(set_to_none=True) # Initialize gradient
output = model4(data) # Forward pass
loss = loss_func(output, target) # Calculate loss
loss.backward() # Backward pass
optimizer.step() # Optimize weights
total_loss.append(loss.item()) # Store loss
loss_list.append(sum(total_loss) / len(total_loss))
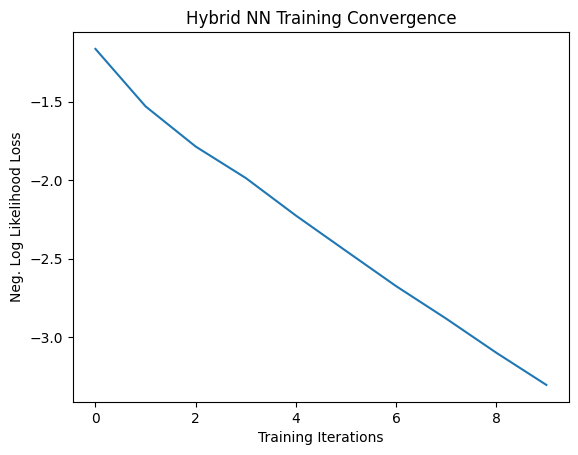
print("Training [{:.0f}%]\tLoss: {:.4f}".format(100.0 * (epoch + 1) / epochs, loss_list[-1]))
Training [10%] Loss: -1.1630
Training [20%] Loss: -1.5294
Training [30%] Loss: -1.7855
Training [40%] Loss: -1.9863
Training [50%] Loss: -2.2257
Training [60%] Loss: -2.4513
Training [70%] Loss: -2.6758
Training [80%] Loss: -2.8832
Training [90%] Loss: -3.1006
Training [100%] Loss: -3.3061
[23]:
# Plot loss convergence
plt.plot(loss_list)
plt.title("Hybrid NN Training Convergence")
plt.xlabel("Training Iterations")
plt.ylabel("Neg. Log Likelihood Loss")
plt.show()
[24]:
torch.save(model4.state_dict(), "model4.pt")
[25]:
qnn5 = create_qnn()
model5 = Net(qnn5)
model5.load_state_dict(torch.load("model4.pt"))
C:\Users\vkasi\AppData\Local\Temp\ipykernel_11904\2057927024.py:3: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
model5.load_state_dict(torch.load("model4.pt"))
[25]:
<All keys matched successfully>
[26]:
model5.eval() # set model to evaluation mode
with no_grad():
correct = 0
for batch_idx, (data, target) in enumerate(test_loader):
output = model5(data)
if len(output.shape) == 1:
output = output.reshape(1, *output.shape)
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
loss = loss_func(output, target)
total_loss.append(loss.item())
print(
"Performance on test data:\n\tLoss: {:.4f}\n\tAccuracy: {:.1f}%".format(
sum(total_loss) / len(total_loss), correct / len(test_loader) / batch_size * 100
)
)
Performance on test data:
Loss: -3.3585
Accuracy: 100.0%
[27]:
# Plot predicted labels
n_samples_show = 6
count = 0
fig, axes = plt.subplots(nrows=1, ncols=n_samples_show, figsize=(10, 3))
model5.eval()
with no_grad():
for batch_idx, (data, target) in enumerate(test_loader):
if count == n_samples_show:
break
output = model5(data[0:1])
if len(output.shape) == 1:
output = output.reshape(1, *output.shape)
pred = output.argmax(dim=1, keepdim=True)
axes[count].imshow(data[0].numpy().squeeze(), cmap="gray")
axes[count].set_xticks([])
axes[count].set_yticks([])
axes[count].set_title("Predicted {}".format(pred.item()))
count += 1

[ ]: