08 - Improving Variational Quantum Optimization using CVaR
[1]:
# This code is from the tutorial at:
# https://qiskit-community.github.io/qiskit-optimization/tutorials/08_cvar_optimization.html
[2]:
from qiskit.circuit.library import RealAmplitudes
from qiskit_algorithms.optimizers import COBYLA
from qiskit_algorithms import NumPyMinimumEigensolver, SamplingVQE
from qiskit_algorithms.utils import algorithm_globals
# Switch to Quantum Rings's Sampler
#from qiskit.primitives import Sampler
from quantumrings.toolkit.qiskit import QrSamplerV1 as Sampler
from qiskit_optimization.converters import LinearEqualityToPenalty
from qiskit_optimization.algorithms import MinimumEigenOptimizer
from qiskit_optimization.translators import from_docplex_mp
import numpy as np
import matplotlib.pyplot as plt
from docplex.mp.model import Model
[3]:
algorithm_globals.random_seed = 123456
[4]:
# prepare problem instance
n = 6 # number of assets
q = 0.5 # risk factor
budget = n // 2 # budget
penalty = 2 * n # scaling of penalty term
[5]:
# instance from [1]
mu = np.array([0.7313, 0.9893, 0.2725, 0.8750, 0.7667, 0.3622])
sigma = np.array(
[
[0.7312, -0.6233, 0.4689, -0.5452, -0.0082, -0.3809],
[-0.6233, 2.4732, -0.7538, 2.4659, -0.0733, 0.8945],
[0.4689, -0.7538, 1.1543, -1.4095, 0.0007, -0.4301],
[-0.5452, 2.4659, -1.4095, 3.5067, 0.2012, 1.0922],
[-0.0082, -0.0733, 0.0007, 0.2012, 0.6231, 0.1509],
[-0.3809, 0.8945, -0.4301, 1.0922, 0.1509, 0.8992],
]
)
# or create random instance
# mu, sigma = portfolio.random_model(n, seed=123) # expected returns and covariance matrix
[6]:
# create docplex model
mdl = Model("portfolio_optimization")
x = mdl.binary_var_list(range(n), name="x")
objective = mdl.sum([mu[i] * x[i] for i in range(n)])
objective -= q * mdl.sum([sigma[i, j] * x[i] * x[j] for i in range(n) for j in range(n)])
mdl.maximize(objective)
mdl.add_constraint(mdl.sum(x[i] for i in range(n)) == budget)
# case to
qp = from_docplex_mp(mdl)
[7]:
# solve classically as reference
opt_result = MinimumEigenOptimizer(NumPyMinimumEigensolver()).solve(qp)
print(opt_result.prettyprint())
objective function value: 1.27835
variable values: x_0=1.0, x_1=1.0, x_2=0.0, x_3=0.0, x_4=1.0, x_5=0.0
status: SUCCESS
[8]:
# we convert the problem to an unconstrained problem for further analysis,
# otherwise this would not be necessary as the MinimumEigenSolver would do this
# translation automatically
linear2penalty = LinearEqualityToPenalty(penalty=penalty)
qp = linear2penalty.convert(qp)
_, offset = qp.to_ising()
Minimum Eigen Optimizer using SamplingVQE
[9]:
# set classical optimizer
maxiter = 100
optimizer = COBYLA(maxiter=maxiter)
# set variational ansatz
ansatz = RealAmplitudes(n, reps=1)
m = ansatz.num_parameters
# set sampler
sampler = Sampler()
# run variational optimization for different values of alpha
alphas = [1.0, 0.50, 0.25] # confidence levels to be evaluated
[10]:
# dictionaries to store optimization progress and results
objectives = {alpha: [] for alpha in alphas} # set of tested objective functions w.r.t. alpha
results = {} # results of minimum eigensolver w.r.t alpha
# callback to store intermediate results
def callback(i, params, obj, stddev, alpha):
# we translate the objective from the internal Ising representation
# to the original optimization problem
objectives[alpha].append(np.real_if_close(-(obj + offset)))
# loop over all given alpha values
for alpha in alphas:
# initialize SamplingVQE using CVaR
vqe = SamplingVQE(
sampler=sampler,
ansatz=ansatz,
optimizer=optimizer,
aggregation=alpha,
callback=lambda i, params, obj, stddev: callback(i, params, obj, stddev, alpha),
)
# initialize optimization algorithm based on CVaR-SamplingVQE
opt_alg = MinimumEigenOptimizer(vqe)
# solve problem
results[alpha] = opt_alg.solve(qp)
print(f"Count of raw samples: {len(results[alpha].raw_samples)}")
print(f"Count of samples: {len(results[alpha].samples)}")
print(type(results[alpha].min_eigen_solver_result))
print(f"Count of eigenstate binary probs: {len(results[alpha].min_eigen_solver_result.eigenstate.binary_probabilities().values())}")
# print results
print("alpha = {}:".format(alpha))
print(results[alpha].prettyprint())
print()
Count of raw samples: 26
Count of samples: 26
<class 'qiskit_algorithms.minimum_eigensolvers.sampling_vqe.SamplingVQEResult'>
Count of eigenstate binary probs: 26
alpha = 1.0:
objective function value: 0.9716499999999968
variable values: x_0=1.0, x_1=0.0, x_2=0.0, x_3=0.0, x_4=1.0, x_5=1.0
status: SUCCESS
Count of raw samples: 25
Count of samples: 25
<class 'qiskit_algorithms.minimum_eigensolvers.sampling_vqe.SamplingVQEResult'>
Count of eigenstate binary probs: 25
alpha = 0.5:
objective function value: 0.7296000000000049
variable values: x_0=0.0, x_1=1.0, x_2=1.0, x_3=0.0, x_4=1.0, x_5=0.0
status: SUCCESS
Count of raw samples: 50
Count of samples: 50
<class 'qiskit_algorithms.minimum_eigensolvers.sampling_vqe.SamplingVQEResult'>
Count of eigenstate binary probs: 50
alpha = 0.25:
objective function value: 1.2783500000000174
variable values: x_0=1.0, x_1=1.0, x_2=0.0, x_3=0.0, x_4=1.0, x_5=0.0
status: SUCCESS
[11]:
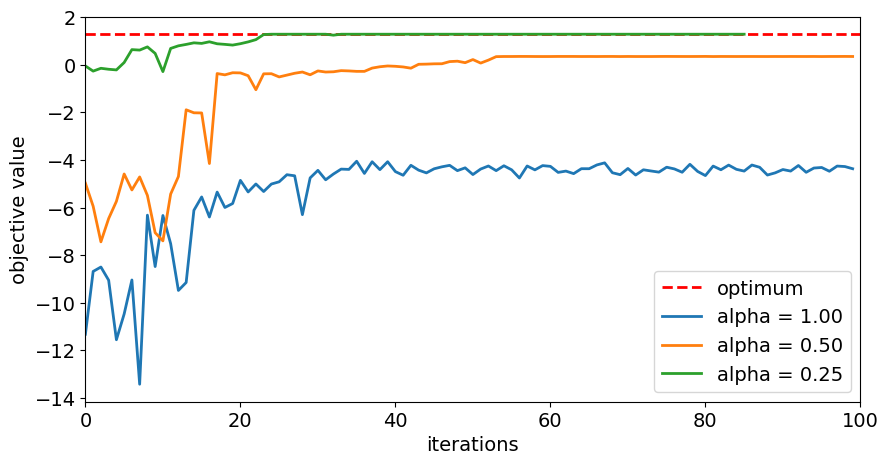
# plot resulting history of objective values
plt.figure(figsize=(10, 5))
plt.plot([0, maxiter], [opt_result.fval, opt_result.fval], "r--", linewidth=2, label="optimum")
for alpha in alphas:
plt.plot(objectives[alpha], label="alpha = %.2f" % alpha, linewidth=2)
plt.legend(loc="lower right", fontsize=14)
plt.xlim(0, maxiter)
plt.xticks(fontsize=14)
plt.xlabel("iterations", fontsize=14)
plt.yticks(fontsize=14)
plt.ylabel("objective value", fontsize=14)
plt.show()
[12]:
# evaluate and sort all objective values
objective_values = np.zeros(2**n)
for i in range(2**n):
x_bin = ("{0:0%sb}" % n).format(i)
x = [0 if x_ == "0" else 1 for x_ in reversed(x_bin)]
objective_values[i] = qp.objective.evaluate(x)
ind = np.argsort(objective_values)
# evaluate final optimal probability for each alpha
for alpha in alphas:
probabilities = np.fromiter(
results[alpha].min_eigen_solver_result.eigenstate.binary_probabilities().values(),
dtype=float,
)
# Fix, because, zero or close to zero states may not be present in the binary_probabilities
# causing a mismatch with the number of items in ind.
if ( len(probabilities) < len(ind)):
probabilities = np.append(probabilities, [0] * (len(ind) - len(probabilities)))
print("optimal probability (alpha = %.2f): %.4f" % (alpha, probabilities[ind][-1:]))
optimal probability (alpha = 1.00): 0.0020
optimal probability (alpha = 0.50): 0.0098
optimal probability (alpha = 0.25): 0.0273
C:\Users\vkasi\AppData\Local\Temp\ipykernel_33812\2091013010.py:22: DeprecationWarning: Conversion of an array with ndim > 0 to a scalar is deprecated, and will error in future. Ensure you extract a single element from your array before performing this operation. (Deprecated NumPy 1.25.)
print("optimal probability (alpha = %.2f): %.4f" % (alpha, probabilities[ind][-1:]))
[ ]: